
Fundamentos da Web
Introdução aos Fundamentos da Web
A Web tornou-se uma das tecnologias mais importantes da sociedade moderna. Atualmente, grande parte das atividades humanas depende de aplicações web: sistemas bancários, redes sociais, comércio eletrônico, educação a distância, streaming de vídeo, serviços governamentais e comunicação instantânea.
Antes de aprender linguagens como HTML5, CSS3 e JavaScript, é fundamental compreender como a Web funciona internamente. Esse entendimento permite que o estudante desenvolva aplicações de maneira mais eficiente, segura e profissional.

História da Web
Internet x Web
Embora muitas pessoas utilizem os termos “Internet” e “Web” como sinônimos, eles possuem significados diferentes.

Internet
A Internet é a infraestrutura mundial de redes interligadas. Trata-se de um gigantesco conjunto de computadores conectados entre si por meio de protocolos de comunicação.
Web (World Wide Web)
A Web é um serviço que funciona sobre a Internet. Ela permite acessar páginas, sites e aplicações utilizando navegadores.
Analogia:
-
Internet → Estradas e rodovias.
-
Web → Automóveis circulando nessas estradas.
Ou seja, a Web depende da Internet para existir.
Origem da Internet
A origem da Internet está profundamente relacionada ao contexto político, militar e científico da segunda metade do século XX. Após a Segunda Guerra Mundial, o mundo passou a viver o período conhecido como Guerra Fria, marcado pela intensa disputa tecnológica, militar e ideológica entre os Estados Unidos e a União Soviética. Nesse cenário, surgiu a preocupação com a criação de sistemas de comunicação mais resistentes e descentralizados, capazes de continuar funcionando mesmo diante de possíveis ataques militares ou nucleares.

Durante a década de 1960, o Departamento de Defesa dos Estados Unidos, por meio da agência ARPA (Advanced Research Projects Agency), iniciou pesquisas voltadas ao desenvolvimento de uma rede de computadores que não dependesse de um único ponto central de controle. O objetivo era evitar que a destruição de um centro de comunicação interrompesse completamente o fluxo de informações militares. Essa ideia representava uma ruptura importante com os sistemas tradicionais de comunicação da época, que eram altamente centralizados.
Desse projeto nasceu a ARPANET, considerada a precursora da Internet moderna. A ARPANET começou oficialmente em 1969 conectando quatro instituições norte-americanas:
- Universidade da Califórnia em Los Angeles (UCLA);
- Stanford Research Institute (SRI);
- Universidade da Califórnia em Santa Barbara;
- Universidade de Utah.
O primeiro teste de comunicação entre computadores ocorreu em 29 de outubro de 1969. Curiosamente, a primeira mensagem enviada pela rede deveria ser a palavra “LOGIN”. Entretanto, o sistema caiu após o envio das duas primeiras letras, “LO”. Mesmo com a falha, esse episódio tornou-se um marco histórico no nascimento da Internet.
Um dos avanços tecnológicos mais importantes desse período foi o conceito de “comutação de pacotes” (packet switching). Diferentemente das redes telefônicas tradicionais, nas quais a comunicação exige um circuito contínuo dedicado, a comutação de pacotes divide as informações em pequenos blocos chamados pacotes. Esses pacotes podem seguir caminhos diferentes pela rede até chegarem ao destino, onde são reorganizados. Esse modelo tornou as redes muito mais eficientes, resilientes e escaláveis, sendo utilizado até hoje na Internet moderna.
Na década de 1970, a ARPANET deixou de ser apenas um projeto militar e passou a ser amplamente utilizada por universidades e centros de pesquisa. Pesquisadores perceberam o enorme potencial da rede para compartilhamento de informações científicas, troca de mensagens e colaboração acadêmica. Nesse período surgiu também o correio eletrônico (e-mail), criado por Ray Tomlinson em 1971. Foi ele quem popularizou o uso do símbolo “@” para separar usuário e domínio em endereços eletrônicos.
Outro marco fundamental ocorreu em 1974, quando os pesquisadores Vinton Cerf e Robert Kahn desenvolveram o protocolo TCP/IP (Transmission Control Protocol/Internet Protocol). Esse conjunto de protocolos permitiu que diferentes redes pudessem se comunicar utilizando um padrão comum. O TCP/IP tornou-se a base da Internet moderna e ainda hoje é utilizado em praticamente toda comunicação digital global.

Em 1º de janeiro de 1983 ocorreu um evento histórico conhecido como “Flag Day”, quando a ARPANET passou oficialmente a utilizar o protocolo TCP/IP. Muitos historiadores consideram essa data como o verdadeiro nascimento técnico da Internet. A partir desse momento, várias redes independentes começaram a se conectar, formando uma grande “rede de redes”, conceito que originou o termo Internet.

Durante os anos 1980, a Internet expandiu-se rapidamente no ambiente acadêmico e científico. Surgiram redes universitárias internacionais, centros de pesquisa conectados globalmente e novos serviços digitais. Entretanto, o acesso ainda era bastante restrito e técnico. A popularização mundial só aconteceria na década de 1990, com o surgimento da World Wide Web criada por Tim Berners-Lee no CERN. A Web introduziu páginas interligadas por hiperlinks, navegadores gráficos e maior facilidade de uso, tornando a Internet acessível ao público em geral.
Atualmente, a Internet conecta bilhões de dispositivos em todo o planeta e sustenta áreas fundamentais da sociedade moderna, como educação, comunicação, comércio, entretenimento, serviços financeiros, inteligência artificial e computação em nuvem. O que começou como um projeto militar experimental transformou-se em uma das maiores infraestruturas tecnológicas já criadas pela humanidade.
Surgimento da Web
A World Wide Web foi criada em 1989 por Tim Berners-Lee, pesquisador do CERN.
Seu objetivo era facilitar o compartilhamento de documentos científicos.
Tim Berners-Lee desenvolveu três elementos fundamentais:
| Tecnologia | Função |
| HTML | Estrutura das páginas |
| HTTP | Comunicação entre computadores |
| URL | Endereço dos recursos |
Essas tecnologias continuam sendo a base da Web moderna.
Evolução da Web
Web 1.0 — Web Estática

Características:
- páginas fixas;
- pouca interação;
- conteúdo apenas para leitura.
Exemplo:
- sites institucionais antigos.
Web 2.0 — Web Interativa

Características:
- interação dos usuários;
- redes sociais;
- produção colaborativa de conteúdo.
Exemplos:
- YouTube;
- Facebook;
- Wikipédia.
Web 3.0 — Web Inteligente
Características:
- inteligência artificial;
- dados conectados;
- personalização;
- computação distribuída.
Exemplos:
- assistentes virtuais;
- sistemas de recomendação;
- aplicações baseadas em IA.
Modelo Cliente x Servidor
Conceito
Grande parte das aplicações web funciona utilizando a arquitetura cliente-servidor.
Essa arquitetura divide as responsabilidades entre dois elementos principais:
| Elemento | Função |
| Cliente | Solicita serviços |
| Servidor | Responde às solicitações |
O Cliente
O cliente normalmente é o navegador utilizado pelo usuário.
Exemplos:
- Google Chrome
- Mozilla Firefox
- Microsoft Edge
O cliente:
- envia requisições;
- interpreta páginas;
- exibe conteúdos;
- executa JavaScript.
O Servidor
O servidor é o computador responsável por:
- armazenar arquivos;
- processar dados;
- executar aplicações;
- responder às requisições dos clientes.
Exemplos:
- servidores web Apache;
- Nginx;
- IIS.
Analogia Cliente x Servidor
Uma analogia bastante útil é a de um restaurante:
| Elemento Web | Restaurante |
| Cliente | Cliente do restaurante |
| Requisição HTTP | Pedido |
| Servidor | Cozinha |
| Resposta | Prato entregue |
O cliente faz um pedido. O servidor processa e devolve a resposta.
Fluxo Básico de Funcionamento
- Usuário digita um endereço.
- Navegador envia uma requisição.
- Servidor processa o pedido.
- Servidor envia uma resposta.
- Navegador exibe o conteúdo.
HTTP e HTTPS
O que é HTTP
HTTP significa:
HyperText Transfer Protocol
É o protocolo responsável pela comunicação entre cliente e servidor na Web.
O HTTP define:
- como pedidos são enviados;
- como respostas são retornadas;
- como os dados trafegam.
Funcionamento Básico
Quando um usuário acessa um site:
- O navegador envia uma requisição HTTP.
- O servidor responde com arquivos HTML, CSS, JavaScript, imagens etc.
Métodos HTTP
Os métodos HTTP representam as ações que um cliente deseja realizar em um servidor durante uma comunicação web. Quando um navegador, aplicativo ou sistema envia uma requisição para um servidor, ele utiliza um método HTTP para indicar qual operação deseja executar. Esses métodos fazem parte do protocolo HTTP (HyperText Transfer Protocol) e são fundamentais para o funcionamento de aplicações web modernas.
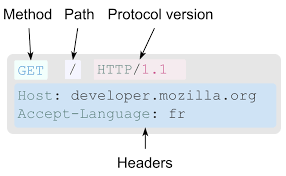
Uma forma simples de compreender os métodos HTTP é imaginar um sistema de biblioteca. O usuário pode:
- consultar livros disponíveis;
- cadastrar novos livros;
- atualizar informações;
- remover registros.
Cada uma dessas ações corresponde a um método HTTP diferente. Assim, os métodos funcionam como “verbos” da comunicação web, indicando claramente a intenção da requisição enviada ao servidor.
Os métodos HTTP mais utilizados em aplicações web são:
- GET;
- POST;
- PUT;
- DELETE.
Método GET
O método GET é utilizado para solicitar informações ao servidor. Ele é o método mais comum da Web e normalmente não altera os dados armazenados no sistema. Seu objetivo principal é apenas consultar ou recuperar informações.
Quando um usuário acessa um site digitando um endereço no navegador, geralmente uma requisição GET é enviada ao servidor. O servidor então responde com os dados solicitados, como páginas HTML, imagens, arquivos CSS ou informações de um banco de dados.
Exemplo:
Um usuário acessa:
https://site.com/produtos
Nesse caso, o navegador envia uma requisição GET pedindo a lista de produtos.
Analogia:
O GET pode ser comparado a consultar um cardápio em um restaurante. O cliente apenas visualiza as opções disponíveis, sem alterar nada no funcionamento do estabelecimento.
Outra característica importante do GET é que os dados enviados podem aparecer na própria URL.
Exemplo:
https://site.com/busca?produto=notebook
Nesse caso:
- produto = parâmetro;
- notebook = valor enviado.
Por esse motivo, o GET não é recomendado para envio de informações sensíveis, como senhas.
Método POST
O método POST é utilizado para enviar dados ao servidor. Diferentemente do GET, o POST normalmente altera o estado da aplicação, criando ou registrando informações.
Esse método é muito utilizado em:
- formulários de cadastro;
- login;
- envio de mensagens;
- upload de arquivos;
- sistemas de pagamento.
Exemplo:
Quando um usuário preenche um formulário de cadastro e clica em “Enviar”, o navegador geralmente utiliza uma requisição POST para transmitir os dados ao servidor.
Analogia:
O POST pode ser comparado ao preenchimento de uma ficha de inscrição em uma escola. O usuário fornece informações que serão armazenadas pelo sistema.
Ao contrário do GET, os dados enviados pelo POST não aparecem diretamente na URL. Eles são enviados no corpo da requisição HTTP, oferecendo maior segurança e organização.
Exemplo simplificado:
POST /cadastro HTTP/1.1
O servidor então processa os dados e pode:
- salvar no banco de dados;
- validar informações;
- retornar mensagens de sucesso ou erro.
Método PUT
O método PUT é utilizado para atualizar ou substituir informações existentes no servidor. Ele é bastante comum em APIs REST e aplicações modernas.
Exemplo:
Imagine um sistema de cadastro de alunos. Um estudante já possui registro no banco de dados, mas deseja atualizar seu endereço ou telefone. Nesse caso, o sistema pode utilizar uma requisição PUT para modificar os dados existentes.
Analogia:
O PUT pode ser comparado à atualização de um cadastro em uma empresa. O registro já existe, mas algumas informações precisam ser alteradas.
Exemplo simplificado:
PUT /usuarios/15 HTTP/1.1
Nesse exemplo:
- usuarios = recurso;
- 15 = identificador do usuário.
O servidor localiza o registro correspondente e atualiza os dados recebidos.
Uma característica importante do PUT é a ideia de substituição ou atualização consistente do recurso. Em muitas arquiteturas REST, o PUT envia uma nova versão completa do objeto.
Método DELETE
O método DELETE é utilizado para remover informações armazenadas no servidor.
Exemplo:
Em um sistema de gerenciamento de tarefas, quando o usuário exclui uma tarefa da lista, o sistema normalmente envia uma requisição DELETE para o servidor.
Analogia:
O DELETE pode ser comparado ao ato de apagar um arquivo do computador ou descartar um documento físico de um arquivo administrativo.
Exemplo simplificado:
DELETE /tarefas/8 HTTP/1.1
Nesse caso:
- tarefas = recurso;
- 8 = identificador da tarefa.
O servidor recebe a requisição e remove o item correspondente do banco de dados.
Por questões de segurança, operações DELETE geralmente exigem:
-
autenticação;
-
permissões específicas;
-
confirmações adicionais.
Isso evita exclusões acidentais ou maliciosas.
Resumo Geral dos Métodos HTTP
| Método | Objetivo Principal | Analogia |
| GET | Consultar dados | Ler um cardápio |
| POST | Enviar/criar dados | Preencher cadastro |
| PUT | Atualizar dados | Atualizar ficha cadastral |
| DELETE | Remover dados | Excluir documento |
Importância dos Métodos HTTP
Os métodos HTTP são essenciais porque padronizam a comunicação entre clientes e servidores. Eles tornam as aplicações:
- organizadas;
- previsíveis;
- interoperáveis;
- escaláveis.
Frameworks modernos como:
- Django;
- Spring Boot;
- Express;
- ASP.NET Core;
- Laravel;
utilizam intensamente esses métodos para construção de APIs e sistemas web profissionais.
Compreender corretamente os métodos HTTP é fundamental para o desenvolvimento de aplicações modernas, especialmente em arquiteturas REST e sistemas baseados em serviços web.
Exemplo de Requisição
Quando o usuário acessa:
https://www.exemplo.com
O navegador envia algo semelhante a:
GET / HTTP/1.1
Host: www.exemplo.com
O servidor então responde com:
- código de status;
- cabeçalhos;
- conteúdo da página.
Códigos de Status HTTP
Os códigos de status HTTP são respostas enviadas pelo servidor para informar ao cliente o resultado de uma requisição realizada na Web. Sempre que um navegador solicita uma página, envia um formulário ou acessa uma API, o servidor responde indicando se a operação foi bem-sucedida, se ocorreu algum erro ou se são necessárias ações adicionais. Esses códigos fazem parte do protocolo HTTP e são fundamentais para a comunicação entre sistemas web.
Uma forma simples de compreender os códigos HTTP é imaginar uma conversa entre duas pessoas. O cliente faz um pedido e o servidor responde indicando o resultado da solicitação. Por exemplo:
- “Tudo ocorreu corretamente”;
- “Você não possui permissão”;
- “O recurso não foi encontrado”;
- “O servidor apresentou problemas”.
Assim, os códigos HTTP funcionam como mensagens padronizadas que permitem que navegadores, APIs e aplicações interpretem rapidamente o resultado de uma operação.
Os códigos HTTP são organizados em categorias numéricas:
| Faixa | Categoria | Significado Geral |
| 100–199 | Informativos | Processamento em andamento |
| 200–299 | Sucesso | Operação realizada com sucesso |
| 300–399 | Redirecionamento | Necessidade de redirecionamento |
| 400–499 | Erro do cliente | Problema na requisição |
| 500–599 | Erro do servidor | Problema interno no servidor |
Principais Códigos HTTP
Código 200 — OK
O código 200 indica que a requisição foi processada com sucesso.
Exemplo:
- o usuário acessa uma página;
- o servidor encontra o recurso;
- a página é exibida corretamente.
Analogia:
É como fazer um pedido em um restaurante e receber exatamente o prato solicitado.
Exemplo de uso:
- carregamento de páginas;
- respostas de APIs;
- downloads concluídos.
Código 201 — Created
O código 201 indica que um novo recurso foi criado com sucesso.
É muito utilizado em APIs REST quando:
- um novo usuário é cadastrado;
- um produto é inserido;
- uma postagem é criada.
Exemplo:
Um formulário de cadastro envia dados ao servidor e o sistema cria um novo registro no banco de dados.
Analogia:
Semelhante ao registro oficial de um novo documento em um cartório.
Código 204 — No Content
O código 204 indica que a operação foi concluída corretamente, mas não existe conteúdo para retornar.
Exemplo:
- exclusão de um registro;
- atualização silenciosa de dados.
Analogia:
É como receber uma confirmação silenciosa de que uma tarefa foi concluída.
Código 301 — Moved Permanently
O código 301 indica que um recurso foi movido permanentemente para outro endereço.
O navegador é redirecionado automaticamente para a nova URL.
Exemplo:
- mudança definitiva de domínio;
- reorganização de páginas.
Analogia:
Semelhante a um aviso de mudança de endereço residencial.
Código 302 — Found (Redirecionamento Temporário)
O código 302 informa que o recurso está temporariamente em outro endereço.
Diferentemente do 301, a mudança não é permanente.
Exemplo:
- páginas em manutenção;
- redirecionamentos temporários.
Código 400 — Bad Request
O código 400 indica que a requisição enviada pelo cliente está incorreta ou malformada.
Exemplo:
- envio de dados inválidos;
- parâmetros incorretos;
- sintaxe inadequada.
Analogia:
É como preencher um formulário com informações incompletas ou ilegíveis.
Código 401 — Unauthorized
O código 401 indica que o usuário não está autenticado.
O servidor exige login ou credenciais válidas.
Exemplo:
- acesso a área restrita sem autenticação.
Analogia:
Semelhante a tentar entrar em um prédio sem apresentar identificação.
Código 403 — Forbidden
O código 403 indica que o servidor entendeu a requisição, mas recusou o acesso.
Diferentemente do 401, o usuário pode até estar autenticado, porém não possui permissão suficiente.
Exemplo:
- usuário comum tentando acessar painel administrativo.
Analogia:
É como possuir ingresso para um evento, mas tentar entrar em uma área VIP sem autorização.
Código 404 — Not Found
O código 404 é um dos erros mais conhecidos da Web. Ele indica que o recurso solicitado não foi encontrado no servidor.
Possíveis causas:
- URL digitada incorretamente;
- página removida;
- link quebrado.
Analogia:
É como procurar um livro em uma biblioteca e descobrir que ele não existe mais no local informado.
Código 405 — Method Not Allowed
O código 405 informa que o método HTTP utilizado não é permitido para aquele recurso.
Exemplo:
- tentar usar DELETE em uma rota que aceita apenas GET.
Analogia:
Semelhante a tentar abrir uma porta utilizando uma chave incompatível.
Código 500 — Internal Server Error
O código 500 indica que ocorreu um erro interno no servidor.
Esse é um erro genérico muito comum quando:
- existe falha no código;
- problemas no banco de dados;
- configurações incorretas.
Analogia:
É como um funcionário de uma empresa reconhecer que houve um problema interno, mas sem conseguir explicar exatamente a causa.
Código 502 — Bad Gateway
O código 502 ocorre quando um servidor intermediário recebe uma resposta inválida de outro servidor.
É comum em:
- proxies;
- balanceadores de carga;
- arquiteturas distribuídas.
Analogia:
Imagine um atendente tentando buscar informações em outro setor da empresa, mas recebendo uma resposta inválida ou incompreensível.
Código 503 — Service Unavailable
O código 503 indica que o serviço está temporariamente indisponível.
Possíveis causas:
- manutenção;
- excesso de acessos;
- sobrecarga do servidor.
Analogia:
Semelhante a uma loja fechada temporariamente para manutenção.
Resumo dos Principais Códigos HTTP
| Código | Significado |
| 200 | OK |
| 201 | Recurso criado |
| 204 | Sem conteúdo |
| 301 | Movido permanentemente |
| 302 | Redirecionamento temporário |
| 400 | Requisição inválida |
| 401 | Não autenticado |
| 403 | Acesso proibido |
| 404 | Página não encontrada |
| 405 | Método não permitido |
| 500 | Erro interno do servidor |
| 502 | Gateway inválido |
| 503 | Serviço indisponível |
Importância dos Códigos HTTP
Os códigos HTTP desempenham papel fundamental no desenvolvimento web moderno. Eles permitem:
- identificar falhas;
- depurar aplicações;
- monitorar servidores;
- melhorar segurança;
- construir APIs padronizadas.
Ferramentas como:
- DevTools do navegador;
- Postman;
- logs de servidores;
- sistemas de monitoramento;
utilizam intensamente os códigos HTTP para análise e diagnóstico de aplicações.
Compreender esses códigos é essencial para qualquer profissional que trabalhe com desenvolvimento web, administração de servidores, APIs ou segurança da informação.
HTTPS
HTTPS significa:
HyperText Transfer Protocol Secure
É a versão segura do HTTP.
O HTTPS utiliza criptografia para proteger:
- senhas;
- dados bancários;
- informações pessoais.
Certificados Digitais
O HTTPS depende de certificados digitais.
Esses certificados:
- validam a identidade do site;
- criptografam a comunicação.
Analogia do HTTPS
HTTP:
- cartão-postal;
- qualquer pessoa pode ler.
HTTPS:
- carta lacrada;
- apenas remetente e destinatário conseguem acessar o conteúdo.
Navegadores Web
O que são Navegadores
Navegadores são programas responsáveis por:
- acessar páginas web;
- interpretar HTML;
- aplicar CSS;
- executar JavaScript.
Principais Navegadores
| Navegador | Motor de Renderização |
| Chrome | Blink |
| Edge | Blink |
| Firefox | Gecko |
| Safari | WebKit |
Renderização de Páginas
Quando uma página é acessada:
- O navegador recebe o HTML.
- Interpreta a estrutura.
- Aplica o CSS.
- Executa JavaScript.
- Renderiza a interface visual.
Ferramentas do Desenvolvedor
Os navegadores modernos possuem DevTools.
Permitem:
- inspecionar HTML;
- testar CSS;
- depurar JavaScript;
- analisar desempenho;
- monitorar requisições HTTP.
DNS
Conceito
DNS significa:
Domain Name System
O DNS traduz nomes de domínio em endereços IP.
Por que o DNS Existe
Computadores se comunicam por números IP.
Exemplo:
142.250.79.206
Entretanto, humanos preferem nomes:
google.com
O DNS faz essa tradução.
Analogia do DNS
O DNS funciona como a agenda de contatos de um celular:
| Agenda | DNS |
| Nome da pessoa | Nome do domínio |
| Número telefônico | Endereço IP |
Fluxo Simplificado
- Usuário digita o domínio.
- Navegador consulta o DNS.
- DNS retorna o IP.
- Navegador acessa o servidor.
Hospedagem
O que é Hospedagem
Hospedagem é o serviço responsável por manter um site disponível na Internet.
O servidor hospeda:
- arquivos;
- bancos de dados;
- aplicações;
- imagens.
Tipos de Hospedagem
| Tipo | Característica |
| Compartilhada | Mais barata |
| VPS | Mais controle |
| Cloud | Escalável |
| Dedicada | Alto desempenho |
Hospedagem Moderna
Atualmente, muitos projetos utilizam:
- computação em nuvem;
- containers;
- deploy automatizado.
Serviços Populares
| Serviço | Finalidade |
| Vercel | Front-end |
| Netlify | Sites estáticos |
| Render | Aplicações web |
| GitHub Pages | Projetos simples |
Estrutura de Aplicações Web
Front-End
O front-end é a parte visual da aplicação.
Tecnologias:
- HTML;
- CSS;
- JavaScript.
Responsabilidades:
- interface;
- interação;
- experiência do usuário.
Back-End
O back-end é a parte responsável pelo processamento.
Responsabilidades:
- regras de negócio;
- autenticação;
- banco de dados;
- APIs.
Linguagens comuns:
- JavaScript (Node.js);
- Python;
- Java;
- PHP;
- C#.
Banco de Dados
Responsável pelo armazenamento persistente das informações.
Exemplos:
- MySQL;
- PostgreSQL;
- MongoDB.
Arquitetura Geral
Uma aplicação moderna geralmente possui:
Cliente → Front-End → API → Back-End → Banco de Dados
Introdução ao MVC
MVC é a sigla para Model — View — Controller. Trata-se de um padrão arquitetural utilizado no desenvolvimento de aplicações para organizar o código de maneira estruturada e modular. O principal objetivo do MVC é separar as responsabilidades da aplicação em diferentes camadas, facilitando o desenvolvimento, a manutenção e a evolução do sistema ao longo do tempo.
Antes do surgimento de padrões arquiteturais como o MVC, era comum que aplicações fossem desenvolvidas de maneira desorganizada, misturando regras de negócio, acesso a banco de dados e interface visual em um único bloco de código. Esse modelo gerava diversos problemas:
- dificuldade de manutenção;
- código repetido;
- baixa reutilização;
- maior probabilidade de erros;
- dificuldade para trabalhar em equipe.
O MVC surgiu justamente como uma solução para esses problemas, propondo uma divisão clara das responsabilidades da aplicação.
A ideia central do MVC é bastante semelhante à organização de uma empresa ou de um setor administrativo. Em uma organização eficiente, cada departamento possui funções específicas:
- atendimento ao público;
- processamento interno;
- armazenamento de informações;
- coordenação das operações.
No desenvolvimento de software ocorre algo semelhante. Cada parte da aplicação deve possuir uma responsabilidade bem definida. Isso torna o sistema mais organizado e mais fácil de compreender.
O termo MVC pode ser dividido em três componentes principais:
| Componente | Responsabilidade |
| Model | Dados e regras de negócio |
| View | Interface visual |
| Controller | Controle e processamento |
Cada componente possui uma função específica dentro da arquitetura.
Model
O Model representa os dados da aplicação e as regras de negócio. Ele é responsável por manipular informações, acessar bancos de dados, validar dados e executar operações importantes do sistema.
O Model não se preocupa com aparência visual nem com interação direta com o usuário. Sua responsabilidade é garantir que os dados sejam tratados corretamente.
Exemplo:
Em um sistema escolar, o Model pode:
- cadastrar alunos;
- consultar notas;
- armazenar disciplinas;
- validar matrículas.
Analogia:
O Model pode ser comparado ao setor administrativo de uma empresa, responsável pelos registros e pelas regras internas de funcionamento.
Em aplicações modernas, o Model normalmente interage diretamente com:
- bancos de dados;
- APIs;
- serviços externos.
View
A View representa a interface apresentada ao usuário. Ela é responsável pela exibição das informações e pela interação visual da aplicação.
A View pode conter:
- páginas HTML;
- formulários;
- tabelas;
- botões;
- menus;
- dashboards.
Seu objetivo é tornar os dados compreensíveis e acessíveis ao usuário final.
Exemplo:
No sistema escolar:
- a tela de login;
- o formulário de matrícula;
- a página de notas;
são exemplos de Views.
Analogia:
A View pode ser comparada à vitrine de uma loja. Ela exibe as informações de forma organizada e agradável para o usuário.
É importante compreender que a View não deve conter regras complexas de negócio. Sua função principal é apenas apresentar informações.
Controller
O Controller funciona como intermediário entre a View e o Model. Ele recebe as ações do usuário, interpreta as solicitações e coordena as operações necessárias.
Quando um usuário:
- clica em um botão;
- envia um formulário;
- realiza um login;
o Controller processa essa solicitação.
Depois disso, ele:
- consulta o Model;
- processa os dados;
- escolhe qual View será exibida.
Analogia:
O Controller pode ser comparado a um gerente de operações. Ele coordena o fluxo de trabalho entre diferentes setores.
Funcionamento Geral do MVC
O funcionamento do MVC ocorre em etapas organizadas:
- O usuário interage com a View.
- A View envia a solicitação ao Controller.
- O Controller processa a requisição.
- O Controller consulta ou altera o Model.
- O Model retorna os dados.
- O Controller seleciona a View apropriada.
- A View exibe o resultado ao usuário.
Essa separação melhora significativamente a organização do sistema.
Analogia do Restaurante
Uma das analogias mais utilizadas para explicar MVC é a de um restaurante.
| MVC | Restaurante |
| View | Garçom |
| Controller | Gerente |
| Model | Cozinha |
Fluxo:
- O cliente faz o pedido ao garçom.
- O garçom leva o pedido ao gerente.
- O gerente coordena a cozinha.
- A cozinha prepara o prato.
- O garçom entrega o pedido ao cliente.
Nesse exemplo:
- o cliente não entra diretamente na cozinha;
- a cozinha não conversa diretamente com o cliente;
- o gerente organiza todo o processo.
O MVC funciona exatamente dessa forma: cada componente possui responsabilidades específicas e bem definidas.
Exemplo de MVC em uma Aplicação Web
Imagine um sistema de login.
Quando o usuário preenche:
- login;
- senha;
e clica no botão “Entrar”, ocorre o seguinte processo:
View
A tela de login exibe:
- campos;
- botões;
- mensagens visuais.
Controller
Recebe os dados enviados pelo formulário e verifica a solicitação.
Model
Consulta o banco de dados para validar:
- usuário;
- senha;
- permissões.
Após o processamento:
- se os dados estiverem corretos, o sistema libera o acesso;
- caso contrário, exibe mensagem de erro.
Vantagens do MVC
A utilização do MVC oferece diversas vantagens importantes no desenvolvimento de software.
Organização do Código
Cada parte do sistema possui uma responsabilidade específica, tornando o projeto mais limpo e compreensível.
Facilidade de Manutenção
Alterações na interface visual podem ser realizadas sem modificar as regras de negócio.
Da mesma forma:
- mudanças no banco de dados;
- ajustes de regras;
- novas funcionalidades;
podem ser implementadas com menor impacto nas demais partes do sistema.
Reutilização
Os componentes podem ser reutilizados em diferentes partes da aplicação.
Exemplo:
-
um mesmo Model pode atender várias Views diferentes.
Trabalho em Equipe
O MVC facilita o desenvolvimento colaborativo.
Exemplo:
- designers trabalham nas Views;
- programadores back-end trabalham nos Models;
- desenvolvedores de integração trabalham nos Controllers.
Escalabilidade
Aplicações organizadas em MVC tornam-se mais fáceis de expandir e evoluir.
Esse fator é essencial em sistemas corporativos e aplicações de grande porte.
Frameworks que Utilizam MVC
Diversos frameworks modernos utilizam o padrão MVC ou arquiteturas derivadas.
| Framework | Linguagem |
| Django | Python |
| Spring MVC | Java |
| ASP.NET MVC | C# |
| Laravel | PHP |
Esses frameworks fornecem estruturas prontas que ajudam os desenvolvedores a organizar aplicações de forma profissional.
MVC no Desenvolvimento Moderno
Mesmo com o surgimento de novas arquiteturas, o MVC continua sendo extremamente importante no desenvolvimento web. Muitos frameworks modernos adaptaram ou expandiram seus conceitos, mas a ideia principal de separação de responsabilidades permanece fundamental.
Além disso, compreender MVC ajuda o estudante a:
- entender frameworks modernos;
- organizar melhor seus projetos;
- produzir código mais profissional;
- trabalhar com aplicações escaláveis.
O MVC é considerado um dos padrões arquiteturais mais importantes da história do desenvolvimento de software e continua sendo amplamente utilizado tanto em aplicações acadêmicas quanto em sistemas empresariais.
Conclusão
Os fundamentos estudados neste módulo constituem a base do desenvolvimento web moderno.
Compreender:
- funcionamento da Internet;
- comunicação cliente-servidor;
- protocolos web;
- DNS;
- hospedagem;
- arquitetura de aplicações;
- MVC;
é essencial para desenvolver sistemas profissionais de maneira consciente e estruturada.
Esses conceitos servirão de alicerce para os próximos módulos do curso, nos quais serão estudados:
- HTML5;
- CSS3;
- JavaScript;
- frameworks modernos;
- integração com back-end.
Atividades Práticas
Atividade 1 — Explorando o Navegador
Objetivo:
- utilizar DevTools;
- inspecionar HTML/CSS;
- analisar requisições.
Atividade 2 — Simulando Cliente x Servidor
Objetivo:
-
representar visualmente o fluxo HTTP.
Atividade 3 — Investigando DNS
Ferramentas:
- nslookup;
- ping;
- whois.
Atividade 4 — Publicação Web
Objetivo:
-
publicar uma página simples no GitHub Pages.
Leituras Complementares
Documentação Oficial
Livros
- HTTP: The Definitive Guide
- Learning Web Design
- Eloquent JavaScript
Cursos
Fim da aula 01